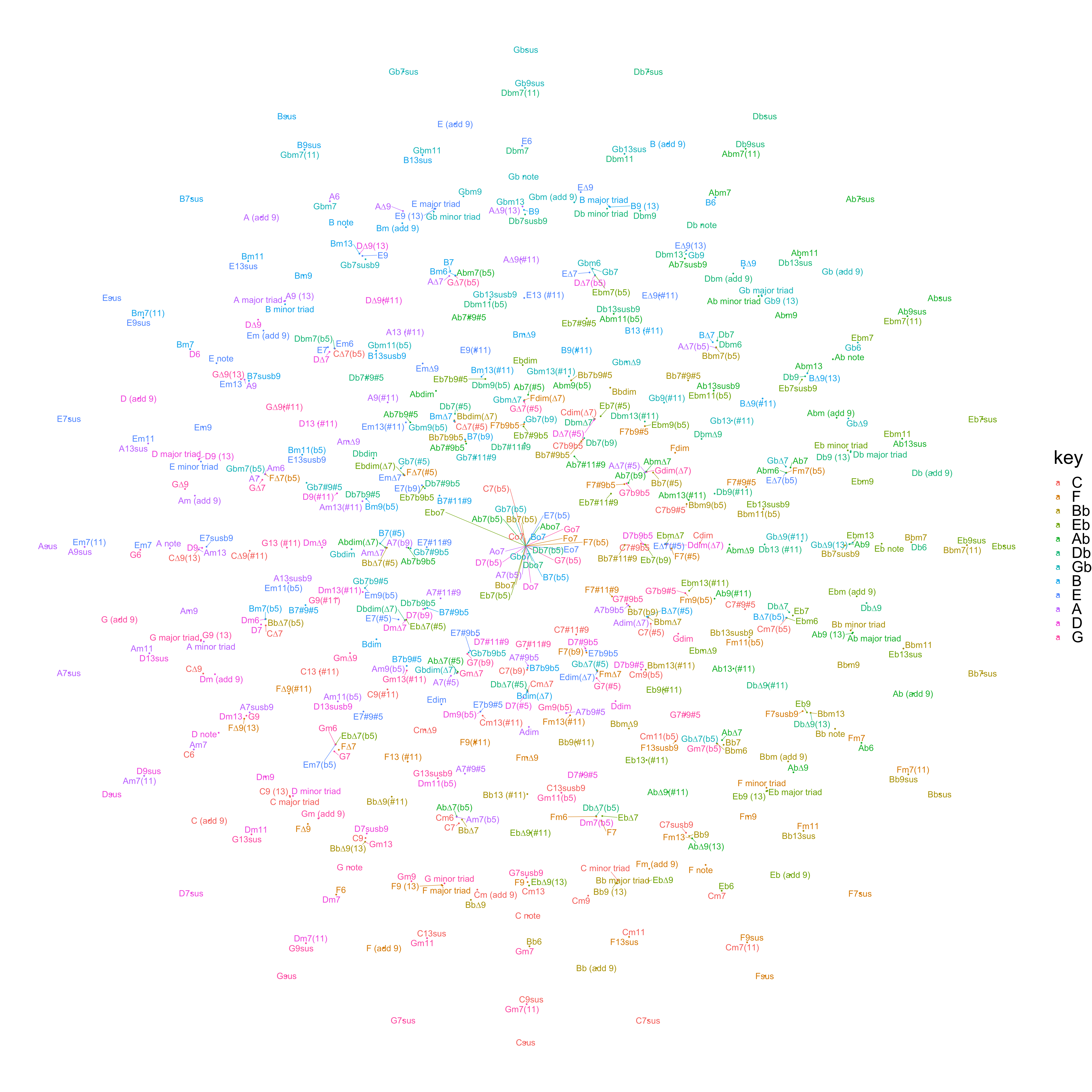
Attempts to visualize version of a chord similarity space
Author
Matt Crump
Published
January 26, 2024
Show the code
from diffusers import DiffusionPipelinefrom transformers import set_seedfrom PIL import Imageimport torchimport randomimport sslimport osssl._create_default_https_context = ssl._create_unverified_context#locate library#model_id = "./stable-diffusion-v1-5"model_id ="dreamshaper-xl-turbo"pipeline = DiffusionPipeline.from_pretrained( pretrained_model_name_or_path ="../../../../bigFiles/huggingface/dreamshaper-xl-turbo/")pipeline = pipeline.to("mps")# Recommended if your computer has < 64 GB of RAMpipeline.enable_attention_slicing("max")prompt ="synthesizer floating in space. 80s cartoon. retro."for s inrange(30):for n in [5,10]: seed = s+21 num_steps = n+1 set_seed(seed) image = pipeline(prompt,height =1024,width =1024,num_images_per_prompt =1,num_inference_steps=num_steps) image_name ="images/synth_{}_{}.jpeg" image_save = image.images[0].save(image_name.format(seed,num_steps))
synthesizer floating in space. 80s cartoon. retro. - Dreamshaper v7
No time today for much explanation. Just some code that produces a visual. Lot’s of things to change up here later.
create feature vectors for chords
calculate similarity matrix
find a multi-dimensional scaling solution to plot the chord names in 2-d
Show the code
library(tidyverse)# pre-processing to get the chord vectors# load chord vectorsc_chord_excel <- rio::import("chord_vectors.xlsx")# grab feature vectorsc_chord_matrix <-as.matrix(c_chord_excel[,4:15])# assign row names to the third column containing chord namesrow.names(c_chord_matrix) <- c_chord_excel[,3]# define all keyskeys <-c("C","Db","D","Eb","E","F","Gb","G","Ab","A","Bb","B")# the excel sheet only has chords in C# loop through the keys, permute the matrix to get the chords in the next key# add the permuted matrix to new rows in the overall chord_matrixfor (i in1:length(keys)) {if (i ==1) {# initialize chord_matrix with C matrix chord_matrix <- c_chord_matrix } else {#permute the matrix as a function of iterator new_matrix <-cbind(c_chord_matrix[, (14-i):12],c_chord_matrix[, 1:(13-i)] )# rename the rows with the new key new_names <-gsub("C", keys[i], c_chord_excel[,3])row.names(new_matrix) <- new_names# append the new_matrix to chord_matrix chord_matrix <-rbind(chord_matrix,new_matrix) }}chord_properties <-tibble(type =rep(c_chord_excel$type,length(keys)),key =rep(keys, each =dim(c_chord_matrix)[1]),chord_names =row.names(chord_matrix),synonyms =list(NA),database_chord =FALSE)first_order <- lsa::cosine(t(chord_matrix))second_order <- lsa::cosine(first_order)# find repeats and build synonym listrepeat_indices <-c()first_occurrence <-c()for(i in1:dim(chord_matrix)[1]){# get the current row evaluate_row <- first_order[i,]# don't count the current item as a repeat evaluate_row[i] <-0# repeats are the ids for any other 1s found repeats <-which(evaluate_row ==1 )if(length(repeats) ==0){ }if(length(repeats) >0){#add to list of repeat items repeat_indices <-c(repeat_indices,repeats)# add synonyms chord_properties$synonyms[i] <-list(synonyms =row.names(chord_matrix)[repeats]) }if(i %in% first_occurrence ==FALSE){if(i %in% repeat_indices ==FALSE){ first_occurrence <-c(first_occurrence,i) chord_properties$database_chord[i] <-TRUE } }}chord_properties <- chord_properties %>%mutate(num_notes =rowSums(chord_matrix),id =1:dim(chord_matrix)[1])# keep only unique chord, recompute similaritieschord_matrix_no_repeats <- chord_matrix[first_occurrence,]first_order_no_repeats <- lsa::cosine(t(chord_matrix_no_repeats))second_order_no_repeats <- lsa::cosine(first_order_no_repeats)# remove scales and individual notesonly_chords <- chord_properties %>%filter(type!="scale", type!="key", database_chord ==TRUE)first_order_chords <- first_order_no_repeats[only_chords$chord_names, only_chords$chord_names]second_order_chords <- second_order_no_repeats[only_chords$chord_names, only_chords$chord_names]
First-order similarity chord-space using 1-hot vectors.